ML & Reproducibility: How to Experiment Like a Pro
Knowing that you can replicate experimental results in ML feels just great. It means your product is ready for production-scale deployment.
The trouble with ML is that workflows are anything but linear. We experiment with different ML algorithms and parameters in an incremental and iterative manner, and making that work reproducible is a hard nut to crack.
⚡ Challenges with ML reproducibility
- End-to-end ML pipelines involve multi-step complex workflows - from pre-processing training data to monitoring models for performance degradation.
- Copying massive training datasets each time we want to experiment isn’t scalable.
- There’s no way to maintain versions of several model artifacts and their associated training data atomically.
- The added complexity of managing versions of structured, semi-structured, and unstructured training data.
- It’s hard to enforce data privacy best practices and data access controls when ML teams create duplicate copies of the same data for collaboration.
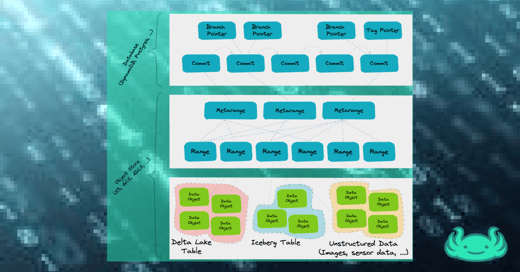
💡 Solution? Data versioning
You can use a data versioning tool that works for data in-place (in object stores) to version training data, ML code, and models together.
📖 How to get started
Check out this guide showing how you can achieve reproducibility via data version control: Building an ML Experimentation Platform for Easy Reproducibility Using lakeFS.
You can also watch this webinar showing how to use lakeFS to intuitively and easily version your ML experiments and reproduce any specific iteration of the experiment as needed.
🛠️ What other people are saying about it
Here’s a primer on data versioning in machine learning: Intro to MLOps: Data and Model Versioning, and a handy tooling guide: How to Version Control Data in ML for Various Data Sources